如何解決 ID3 標籤亂碼問題
最近在 CD 堆中找到和實體書失散的歡樂三國志英雄慶功版1,於是我就想用我的筆電把 CD 讀出來聽,在我的 Linux mint 打開以後,我發現 ID3 標籤原本的編碼格式我的電腦讀不出來,顯示的是無法正常閱讀的亂碼,雖然在播放軟體裡面雖然還是可以辨識出同章節的接著播,但看上去就是有些彆扭。我很確定這一定是 only can Work in Windows computer 的問題,強迫 Linux 用正確的編碼格式去解讀它應該就沒問題了。我覺得直接用 Picard 或 easytag 這種軟體手動把 ID3 標籤原本的字重新打一次很麻煩,直接寫 shell script 轉碼會比重打快一些,要做的事很簡單,只要把這些檔案抓出來重新換編碼寫入就行了,這篇 post 教你怎麼一步一步找出問題並用指令解決。
1:這是侯文詠和蔡康永一起出的書,本體是一本有聲書,當然也可以只看書裡面的字,但就沒那麼有 fu。慶功版是我國小的時候出的重製版,前陣子蔡康永到博音訪談才知道這系列在博恩、howhow 這些七年級生小時候就有了
一開始我先用了 id3v2 這個指令查看 ID3 訊息,可以看到 TPE1 作者欄位是 «J¤åµú.½²±d¥Ã。
id3v2 -l 01皇帝,快跑!\(上\).mp3
id3v1 tag info for 01皇帝,快跑!(上).mp3:
Title : Artist: �J���.���d��
Album : �w�֤T���01-�ӫ�,�ֶ]!-�W Year: , Genre: Speech (101)
Comment:
id3v2 tag info for 01皇帝,快跑!(上).mp3:
TALB (Album/Movie/Show title): Åw¼Ö¤T°ê§Ó01-¬Ó«Ò,§Ö¶]!-¤W
TCON (Content type): Speech (101)
TPE1 (Lead performer(s)/Soloist(s)): «J¤åµú.½²±d¥Ã
因為是中文 CD ,我合理懷疑它原本使用的是 big5 ,貼到一個可以轉換編碼的地方例如 CyberChef 試試看。
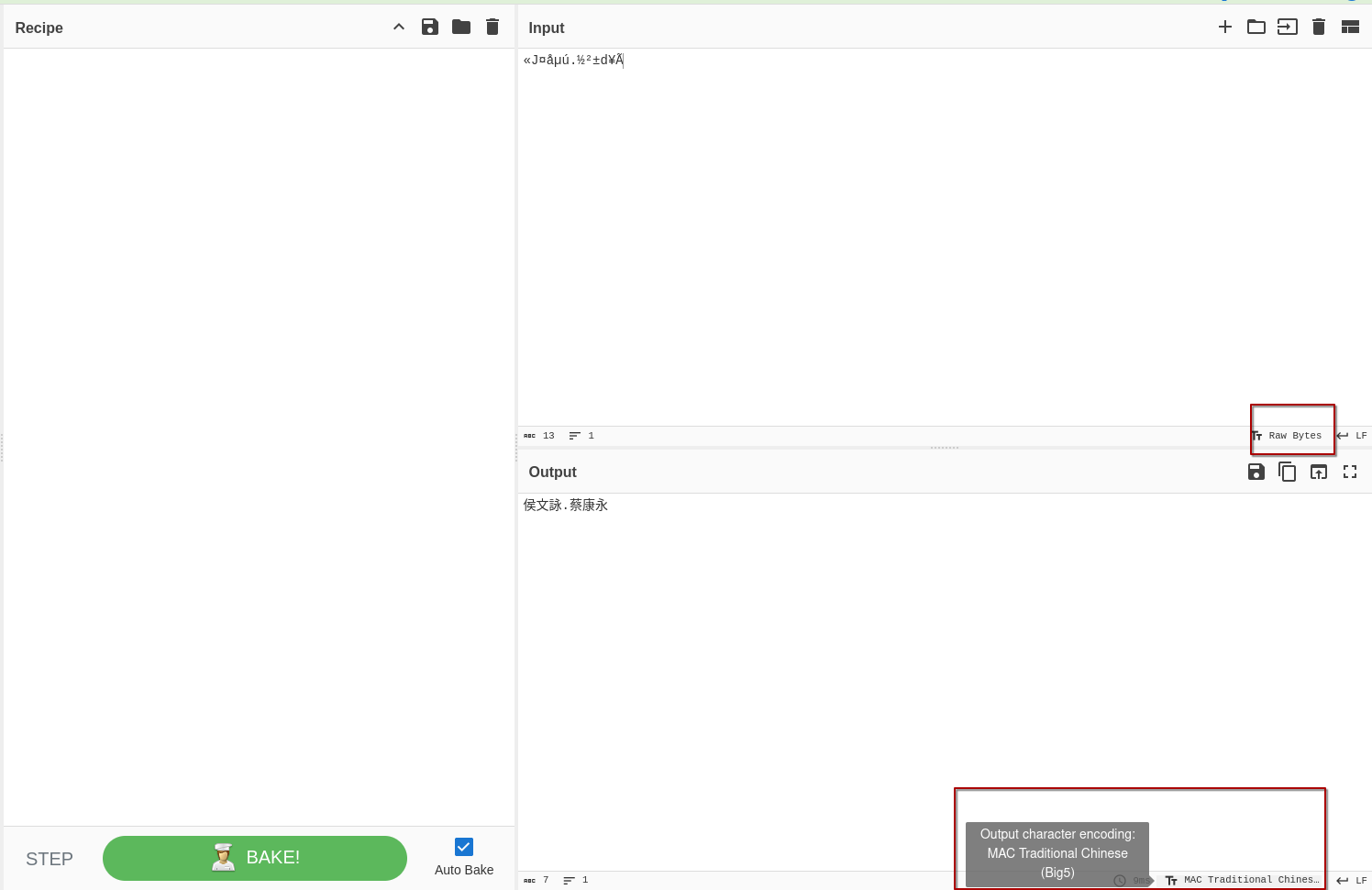
沒錯,轉回來了!接下來再反向驗證一次,在 Recipe 使用 To Hex 會得到 \xab\x4a\xa4\xe5\xb5\xfa\x2e\xbd\xb2\xb1\x64\xa5\xc3,拿給 iconv 驗證一下:
$echo -e '\xab\x4a\xa4\xe5\xb5\xfa\x2e\xbd\xb2\xb1\x64\xa5\xc3' | iconv -f big5 -t utf8
侯文詠.蔡康永
看起來也沒有問題,那就從 CD 複製一份出來改吧!
$ mid3v2 -l "01那一夜,張飛喝醉了酒(上).mp3"
IDv2 tag info for 01那一夜,張飛喝醉了酒(上).mp3
TALB=Åw¼Ö¤T°ê§Ó03-¨º¤@©],±i¸³Ü¾K¤F°s-¤W
TCON=Speech
TPE1=«J¤åµú.½²±d¥Ã
$ mid3iconv -e big5 "01那一夜,張飛喝醉了酒( 上).mp3 "
Updating 01那一夜,張飛喝醉了酒(上).mp3
$ mid3v2 -l "01那一夜,張飛喝醉了酒(上).mp3"
IDv2 tag info for 01那一夜,張飛喝醉了酒(上).mp3
TALB=歡樂三國志03-那一夜,張飛喝醉了酒-上
TCON=Speech
TPE1=侯文詠.蔡康永
所以我們知道這樣改可以正確變換成可以識別的文字,最後在音檔的根目錄結合 find 指令找到所有 mp3 檔。
find ./ -iname "*.mp3" -exec mid3iconv -e big5 "{}" \;
Done!現在就好讀多了,不過我不知道這樣的檔案拿到 Windows 還能不能辨識(轉換前可以),反正這不太重要,我只會在 Linux 打開他們。不過用 mid3v2 轉換完後 id3v2 指令會讀不出東西,蠻怪的。